
In the previous application I wrote, I explored the apple IOS GUI and MVC structure. To take the app further I decided it would be cool to turn it into a word prediction application.
There are 2 parts to predicting words, 1 is determining which word could fill in the sequence and 2 is learn it. Now learning algorithms and providing training data is a whole other game and field but definitely something I look forward to trying in the future. For now the goal is simple, use the character sequence provided in our “filter” to organize our words by best fit. The current plist I have contains approximately 200,000 words. Now according to some google searching, there are over a million to actually choose from so the app maybe a bit behind in word choices. Nevertheless it is still a fun task to try!
So, how what do we do once we have a character sequence provided? Well here is how I think it could work.
If we have a character sequence “TH” we want to filter our list to a sub-list that only contains the characters TH as a prefix.
Here is some sample code:
- (NSMutableArray *)sortWithSquence:(NSString *)sequence
{
if([sequence isEqualToString:@""]) //if no filter, return the regular list
{
return _tableData;
}
sequence = [sequence uppercaseString]; //the sequence will be case sensitive and the list is all uppercase
//remake the filtered list
[_filteredList removeAllObjects];
for(NSString *str in _tableData) //loop through entire set each time for now ..
{
if([str hasPrefix:sequence]) //create a sub group of words that contain the prefix
{
[_filteredList addObject:str];
}
}
return _filteredList;
}
Now the boring thing to do would be to return the top 3 elements in the new filtered list and offer them as options. When searching for “the” the top 3 searches are “the”, “thea”, “theacea”.
Now I don’t think these are really common options and since I do not have commonality statistics to sort by I am going to only fine elements that contain the sequence and are of the same length of the sequence. If no words are of the same length I will add 1 to the length and look again. I will repeat the process until I find words that fall under the shortest length and fill a mini group of 3. In theory this should help me find words like “then” and “their”.
Now in the following code you will notice I first create a sub-list then perform the little algorithm over the sub-list. I will later have my list organized into subarrays based on the first letter. This will greatly reduce sorting through unwanted areas. Ideally there will be a sub-array for each letter of the alphabet and the words will be sorted by shortest to longest length for ease of prediction.
- (NSMutableArray *)sortWithSquence:(NSString *)sequence
{
if([sequence isEqualToString:@""]) //if no filter, return the regular list
{
return _tableData;
}
sequence = [sequence uppercaseString];
NSUInteger lenCompare = [sequence length]; //get an inital length and add one to predict next possible word
NSMutableArray *tempFilteredList = [[NSMutableArray alloc] init];
//remake the filtered list
[_filteredList removeAllObjects];
for(NSString *str in _tableData) //loop through entire set each time for now ..
{
if([str hasPrefix:sequence])
{
[tempFilteredList addObject:str];
}
}
NSInteger repeatCounter = 0;
while([_filteredList count] < 3) //keep going till we have 3 elements { NSUInteger curListSize = [_filteredList count]; for(NSString *str in tempFilteredList) //loop through the new smaller filtered list { //ok we have the sequence lets check if its the right length if([str length] == lenCompare) { NSLog(@"Found match: %@", str); [_filteredList addObject:str]; //stop when we have 3 matches if([_filteredList count] == 3) { return _filteredList; } } } lenCompare++; //go up by 1 length if(curListSize == [_filteredList count] && repeatCounter > 1)
{
//no new matches found with inc compare size, stopping
NSLog(@"No new matches found for %@", sequence);
return _filteredList;
}
else
{
NSLog(@"Not enough matches found, inc lencompare");
}
repeatCounter++;
}
return _filteredList;
I also added a repeat counter to prevent continuously searching for new words if none are found.
Now here is a look at the final product:
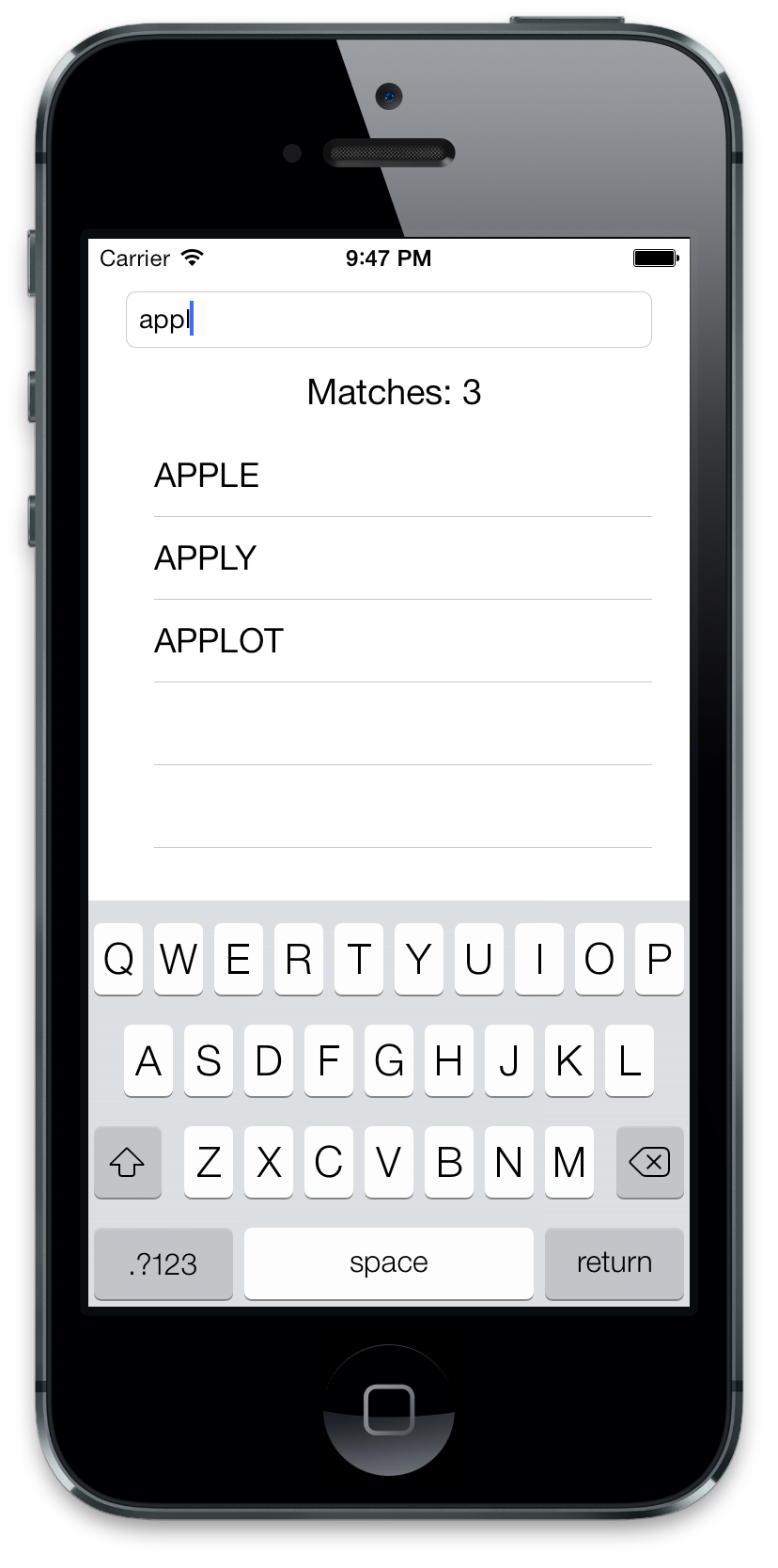
This concludes the changes for now, I will branch the textview into a word prediction repo. To it I will add the initial model word organization for faster sorting time. I will add system to make sentences and use the list to help complete the wording.
Note I will not really target core linguistics here but I will add thoughts on what I would do if I had a pretty little(big) database.
[“word”][“type of word”][“commonality”][“linking word”][“most-used-in-conjunction-with-reference”]
Having data like that would allow a predictor to utilize many factors into determining which word is most likely to finish the sequence. The other key factor is learning and from a reading by Ray Kurzweil, his approach is using Hierarchal Hidden Markov Models or HHMM for short. These learning algorithms allow letters, words and sentences (referred to as nodes) to create links to one another. These nodes form branches or links to one another with probability values.
For example:
The character sequence “APP” may form links to “APPLE, “APPLICATION”, “APPLY”. Each link can be described by a probability value.
APP — 0.5 –> APPLE
— 0.3 –> APPLICATION
— 0.3 –> APPLY
Using Markov models we can denote that apple should be the first choice. In essence we are looking for the translation from one state to another state. This is the simpliest version of the Markov model known as Markov Chains.
